Agent Challenges & Industry Shifts – March 2025 Report
Introducing a New Format
In March 2025, our AI Monthly Report took on a fresh format by launching an in-person “AI Brainstorm” event. Centered around a hot AI topic every month, we invited academic researchers, industry practitioners (including R&D and technical professionals), and investors for a closed-door roundtable discussion.
On March 30, we held the very first AI Brainstorm with the theme Agent. Six guests—from universities, Internet companies, and non-profit AI research institutions—joined the discussion. In this month’s report, we’ve excerpted key parts of the conversation.

In This Issue, You’ll Discover:
- Why Developing Agents Is Easy, But Making Them Work Is Hard
- Key takeaways from the “Shell vs. Model” segment during the event
- The potential of large-model applications to become the internet’s traffic gateways along with OpenAI’s platform vision
- How divergent compute investments have kept Nvidia’s stock in turmoil – Jensen Huang shared an intriguing inference story
- Active merger and acquisition deals with Nvidia leading the charge
- News that 31 AI companies have secured over $50 million in financing, with vertical AI applications capturing investor favor
- Six case studies using a “microscope” approach to trace the internal decision paths of large models
Feel free to leave comments with any important trends we might have missed.
Developing Agents: Easy to Build, Hard to Refine
Earlier in March, the general-purpose Agent product Manus was launched. Just one day later, two open-source versions—OpenManus and OWL—emerged. OpenManus was even replicated by a team of four in merely three hours.
Such “quick and dirty” remakes suggest that building an Agent may not be difficult at first glance. However, practical experiences and system complexity show that making an Agent truly effective remains a significant challenge.
After collaborating with dozens of teams, large-model companies like Anthropic now classify Agents into two categories [1]:
- Workflows: Systems built with a pre-defined code path that coordinate large models with various tools.
- Agents: Systems where the large model autonomously chooses its processing steps and tool usage to complete tasks independently.
The ease in Agent development is largely driven by a maturing foundation of underlying models, frameworks, and tool ecosystems. Companies like OpenAI and Anthropic offer model APIs, and open-source standards now exist to interface with browsers, file systems, search, and more. Anthropic’s recently introduced Model Context Protocol (MCP) is being widely adopted to standardize how Agents connect with external tools—OpenAI has joined this initiative.
Despite these advancements—whether it’s Manus and its various open-source derivatives or OpenAI’s Deep Research Agent—problems continue to arise:
- Large Model Limitations:
Models still suffer from severe hallucinations, logic leaps, challenges in processing long texts, and outdated training data. Even with RAG (Retrieval-Augmented Generation) as a fallback, these issues may introduce further errors. - System Design Challenges:
Precisely guiding model behavior is hard. When executing complex tasks, models can fall into infinite loops, and error accumulation worsens with longer task chains. Furthermore, the limited publicly available information is designed for human interaction rather than for large models.
Anthropic has offered several suggestions for tool-level improvements [1]:
- Think from the model’s perspective—a good tool definition typically includes usage examples, edge cases, and clear input formatting that sets it apart from others.
- Continuously test how the model uses the tool and iterate by learning from its mistakes.
- Implement “poka-yoke” (foolproofing) by tweaking parameter settings to lower the probability of model errors.
“The Model Is the Product”
Alexander Doria from AI startup Pleias insists that “the model is the product” [2]. He explains that OpenAI’s Deep Research did not wrap the o3 model into a product but instead trained a new model through reinforcement learning to give it search capabilities—rather than just calling external tools, adding prompt words, or chaining tasks.
Currently, most Agent products are workflow-based. While these can add value in vertical scenarios, major breakthroughs require a complete model redesign. Focusing solely on application development is like “using a general from one war to fight another.”
During our AI Brainstorm, the discussion “Is the Shell More Important Than the Model for an Agent?” produced several key points:
- Third-Party vs. In-House Products:
Anthropic’s CPO Mike Krieger mentioned that understanding the distinction between “in-house” and “third-party” products is insightful. For instance, Cursor—a successful third-party product—did not train its own large model but impressed with its interaction design, creating an immersive Agent experience that aligns seamlessly with human and production environments. - The Shell Is a Starting Point:
For an Agent, the shell is at least the initial layer. If your shell is forward-thinking, you can wait for the model to improve, and then your product evolves accordingly. - OpenHands’ Early Model:
OpenHands began as a shell with plans for model training down the line. Integrating a commercial model API did not hinder user adoption. They believed that if the shell worked well enough for early users, that was sufficient for the time being. Notice how the steady improvements from Claude 3.5 to 3.7 have reinforced this view. - Packaging as Input/Output Transformation:
The “shell” can be seen as a transformation layer that formats inputs and outputs for the base model. When one side becomes exceptionally strong, the other’s influence on overall performance might lessen. - MCP’s Role:
Anthropic’s MCP further boosts the value of Agent products. This open ecosystem protocol lets any company wrap existing software so that large language models can call it as a tool. - Iterative Model Improvements:
Pre-training, fine-tuning, and Agent architecture optimization work hand-in-hand. Research on DeepSeek and other inference models shows that continuous iteration of the base model is crucial for inference performance—this development stems from the shift from RL-based to LLM-based architectures. - Slowing Iterations:
Base model updates remain key to enhancing Agent performance. However, the speed of these iterations has slowed due to diminishing returns (the Scaling Laws’ marginal gains) and the rising resource barriers that concentrate “model ownership” among top-tier companies. - Vertical Integration Over Disruption:
The evolution of large models will likely push leading vertical application providers to upgrade rather than completely disrupt market dynamics. In the race for super applications, success will depend on robust ecological channel building and rapid integration of local services like maps, payment, and lifestyle, gradually transforming user interaction from simple Q&A to embedded daily experiences. - From Generic Tech to Domain-Specific Expertise:
Much like the shift from the Internet era to the mobile era, the intelligent application era driven by large models marks a transition from general-purpose technology to enhanced domain expertise. In the future, the barriers for Agent applications will shift from pure engineering challenges to the accumulation of user insights, scenario knowledge, and industry understanding.
Large Model Applications as the Gateway to the Internet
In March, OpenAI CEO Sam Altman was asked in an interview [3]:
“In five years, what will be more valuable: a website with 1 billion daily active users that requires no customer acquisition, or the most advanced model?”
After a two-second pause, he chose “a website with 1 billion daily active users.” Altman envisions OpenAI as the gateway to the Internet—users would use their OpenAI accounts with usage credits or custom models to access any third-party service integrated with the OpenAI API.
He said, “This is truly the key to becoming a great platform.”
This vision has already begun to emerge in OpenAI’s Agent product Operator, released in January. Operator can search the web to plan travel, write reports, provide shopping advice, and integrate with services such as DoorDash, Uber, and eBay. Although Operator hasn’t yet made a huge impact, the trend of large-model applications driving web traffic is becoming unmistakable.
Adobe Analytics revealed [4] that since September 2024 the traffic driven by large-model applications has doubled every two months. In the last two months of last year, this traffic grew 1200% year-over-year. Relative to traditional sources, this AI-driven traffic sees an 8% longer website dwell time, 12% more page views, a 23% lower bounce rate, and—though conversion rates are 9% lower—they’re still on the rise. Additionally, a survey of 5000 U.S. consumers found nearly 40% are using AI-assisted shopping, and over half plan to do so later this year.
Many e-commerce and local services heavily depend on on-site recommendation advertising (think Amazon, Alibaba, JD.com, Pinduoduo, Meituan, etc.). If an AI—not a human—is visiting these sites, will the traditional ad systems still be effective?
At the February earnings call, when asked about how Agents might affect its e-commerce business, Amazon CEO Andy Jassy offered an ambiguous answer: “Most retailers already have some form of interaction with Agents, and we’re no different.”
Meanwhile, Walmart’s U.S. CTO Hari Vasudev proposed a countermeasure: “Build your own Agent to interact with other Agents, recommend products, or provide more detailed product information.”
An AI strategy expert at the roundtable noted that even if the primary traffic channels change, the established giants and companies with deep industry expertise will retain a competitive advantage. With the gap between open-source and closed-source model performance narrowing, application vendors can now afford low-cost model capabilities—finetuning a domain-specific model with supervised data (SFT) becomes feasible. Companies that have historically accumulated users, data, and IT capabilities are better positioned in this competition.
The Compute Investment Debate & Nvidia’s Inference Story
In March, the debate over compute investment continued, with Nvidia’s stock experiencing persistent fluctuations: a 13% drop in the first 10 days of the month, a rebound, then another fall.
This volatility stems from two key unresolved issues:
- Will compute consumption shift from training to inference, and will Nvidia’s GPUs remain the only choice?
- Are current compute investments nearing saturation?
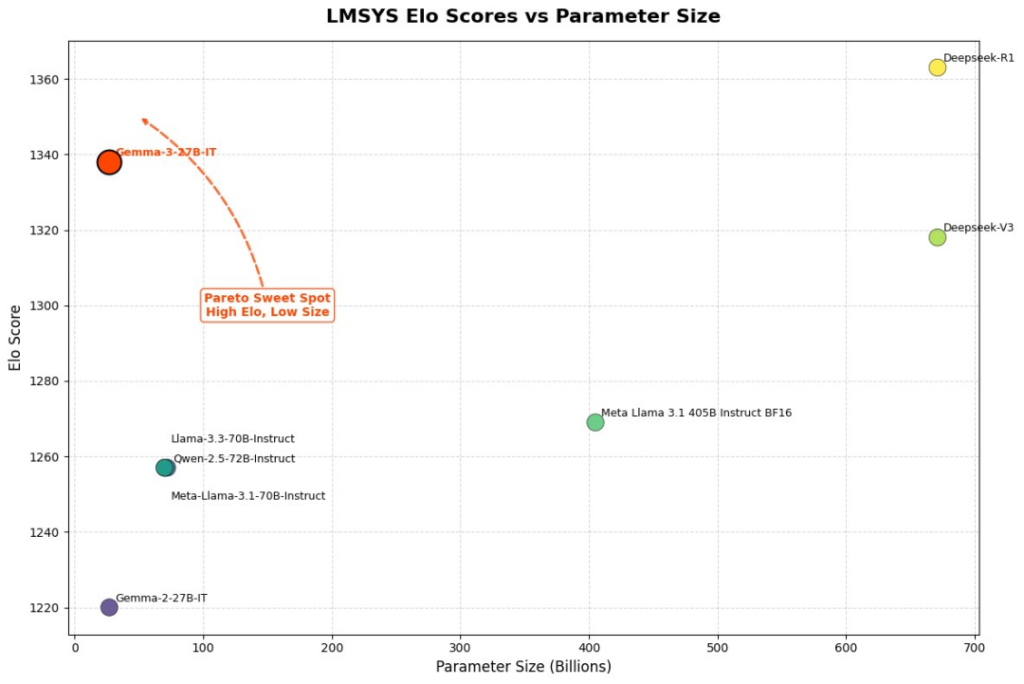
Recent signs even suggest a potential oversupply of compute power:
- Smaller Models, Better Performance:
Google’s open-source 27-billion parameter Gemma 3 model outscored the older DeepSeek-V3 (with 671 billion parameters activated at 37 billion per answer) in Chatbot Arena; Alibaba’s 32-billion parameter inference model QwQ almost matches R1’s performance. - Cutting AI Spend:
Media reports indicate that because companies like DeepSeek, Alibaba, and Google have released models that require less compute but still perform well, many U.S. companies have cut back on their AI expenditures. - Competitive Pricing & New Chips:
AWS is selling its Trainium chips (with the same compute as Nvidia’s H100) at 25% of the price, while Google is working with MediaTek to lower AI chip costs further.
After Microsoft CEO Satya Nadella, Alibaba Chairman Jack Ma warned that some U.S. data centers might be building new facilities at “bubble” prices. Yet, Apple—previously reluctant to work with Nvidia—has started purchasing Nvidia chips, renewing market confidence.
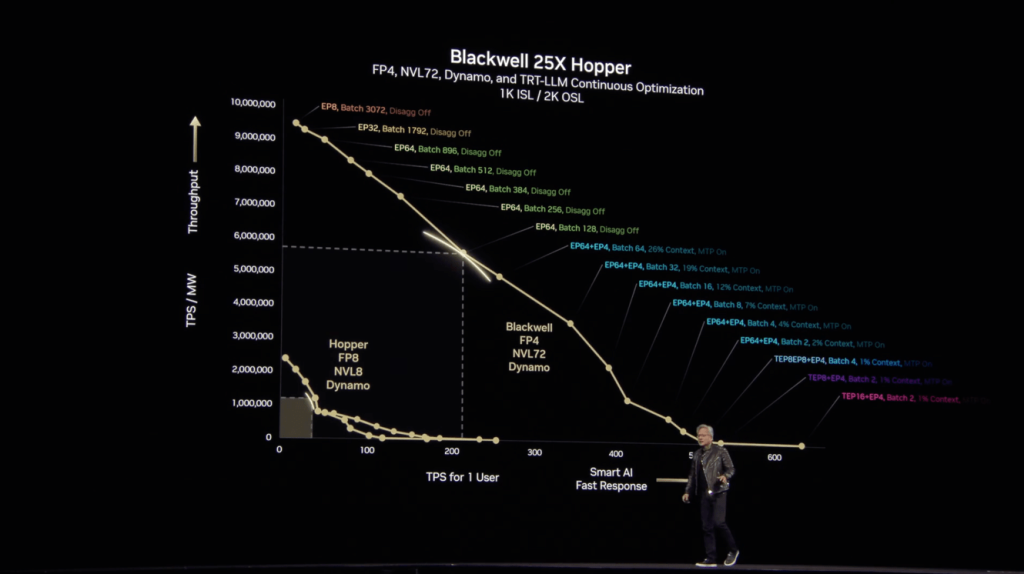
At the March GTC, Nvidia CEO Jensen Huang shared a new inference story:
- Increased Inference Demand:
After OpenAI introduced the o1 inference model, the demand for AI compute shot up to 100 times Nvidia’s expectations from last year. Inference-capable AI deconstructs problems step by step, approaching and choosing the best answers in multiple ways. The number of tokens generated can easily exceed previous models by a hundredfold. - Power Constraints & GPU Advantage:
With data centers facing limited electrical resources, Nvidia’s B-series GPUs deliver 25 times the performance of the H-series at the same power consumption. The upcoming Vera Rubin architecture, expected in 2026, should further amplify this efficiency.
Nvidia’s Dynamo software dynamically adjusts how GPUs handle token processing to maintain both user experience and computational efficiency. Huang summed it up: “When the B-series GPUs start shipping in bulk, you won’t even be able to give away the H-series for free.”
Previously, his catchphrase was “the more you buy, the more you save”—now it’s “the more you buy, the more you earn.”
Not every task requires an inference model. Smaller inference models—such as o3 mini or QwQ-32B—can also perform well. Ultimately, while inference does raise token consumption, whether it will escalate a hundredfold remains to be seen.
At the event, an expert in AI inference commented:
“Agent applications that seem to consume an excessive amount of compute still have significant room for optimization. When Agents browse the web to fetch information, they might capture massive amounts of irrelevant data (for example, screenshots where 99% of the pixels are useless), which greatly increases compute costs.”
Mergers, Acquisitions & Funding Trends
M&A Activity and Strategic Expansion:
In March, the announced volume of major M&A deals exceeded the total of the previous three months—with six transactions valued at over $100 million publicly revealed, and several more still under negotiation.
The AI industry is shifting from competing solely on technology or products to integrating entire ecosystems. Leading companies are actively broadening their business boundaries and building ecological moats. For example:
- Nvidia acquired synthetic data company Gretel for $320 million and is negotiating a multi-hundred-million-dollar deal to acquire Lepton AI (founded by Alibaba’s former VP, Jia Yangqing) to expand from compute acceleration to inference and data services.
- Elon Musk’s xAI is using equity to acquire Twitter (rebranded as X), integrating data, models, compute, distribution channels, and talent. In this deal, xAI is valued at $80 billion and X at $33 billion.
- Google, ServiceNow, and UiPath have made significant acquisitions to expand their enterprise service ecosystems.
At the same time, CoreWeave—a startup specializing in GPU compute leasing backed by Nvidia investments—went public, raising $1.5 billion after earlier plans for a $4 billion raise.
Funding Trends in Vertical AI Applications:
In March, 31 AI companies raised more than $50 million, an increase of eight from the previous month. Funding appears steady, with headlining deals in the base model space:
- OpenAI raised an additional $40 billion, bringing total funding to $58.6 billion with a valuation above $300 billion.
- Anthropic secured $3.5 billion, totaling $18 billion in funding and reaching a $61.5 billion valuation.
In China, companies like Zhipu announced investments from state-owned funds across Hangzhou, Zhuhai, and Chengdu totaling ¥1.8 billion, cumulatively surpassing ¥10 billion, marking milestones in corporate restructuring and preparations for public listing.
Meanwhile, in the infrastructure domain, companies in GPU compute leasing and AI chip development (such as Israel’s Retym and Nexthop AI) have also received significant investments.
Turing—providing programming data for OpenAI, Google, and others—raised $111 million at a $2.2 billion valuation, with annual revenues of $167 million and proven profitability.
Scale AI is now pushing an old-stock deal valued at $25 billion, an 80% increase from May last year, while also expanding into data collection services for humanoid robotics.
Humanoid Robotics See a Funding Surge:
Domestic projects like Zhiyuan Robotics, Tashi Intelligence, Qianxun Intelligence, and Vitadyn have all closed deals at the ¥100+ million level, with the highest valuation reaching ¥15 billion.
Overseas, Agility Robotics raised $400 million, Dexterity secured $95 million, and Apptronik raised $350 million (plus an additional $50 million following a previous $350 million round). SoftBank led a $130 million round for Terabase Energy, which uses robotics to build solar farms.
Application-Focused Funding:
Large-scale funding is predominantly flowing into startups using large-model technology to transform vertical industries—ranging from programming, healthcare, enterprise data services, financial fraud prevention, logistics, to drug discovery—with at least 18 companies in this space.
Most of these companies were founded before ChatGPT’s release, and have already accumulated stable customers and data resources. They aren’t simply wrapping a large model—they’re striving to integrate large models with vertical scenarios, using AI to transform traditional processes and unlock new growth.
Many investors view this direction as a prime entrepreneurial opportunity, noting that these areas demand long-term, deep accumulation to become competitive, and the potential revenue scale hasn’t yet reached the level that attracts the giants. Several Silicon Valley investors told the media that they are now inundated with AI application startup proposals covering the entire industry.
Peering Into the “Black Box”: The AI Microscope
Even though the output from large models can appear reasonable, the internal decision process is opaque







The breakdown of Workflows vs Agents by Anthropic is super helpful.
Seems like everyone is racing to wrap tools around LLMs instead of actually improving them.
I love how OpenManus was replicated in just 3 hours by 4 people—wild.
The Shell vs Model debate is underrated. Both matter, but context decides.
I’m curious if MCP will become a standard like HTML or fade like Flash.
Altman picking 1B DAU over cutting-edge models makes total business sense.
Claude 3.5 to 3.7 evolution shows why keeping up with model iterations is key.
Honestly, the part about how ‘Agents are easy to build but hard to perfect’ hit hard.
The Operator feature by OpenAI sounds like a glimpse into an AI-powered internet.
This AI Brainstorm event sounds like a great way to keep up with emerging trends!
You’re absolutely right, I really appreciate you
Adobe’s traffic stats really show how AI is already reshaping eCommerce.
That 1200% traffic increase from AI tools is absolutely insane.